
外部キーを設定すればテーブル間のデータの関連性を表現でき、データを更新・削除する際にも整合性を保つことができます。本記事では外部キーの概要から作成方法まで基礎から解説します。
外部キーとは
SQLの外部キー(Foreign Key)とは、データを追加・更新・削除する際、テーブル間で制約を設けることで、親テーブルに存在しないデータを子テーブルが持つことがないようにする仕組みです。外部キーを設定することで、テーブル間のデータの関連性を表現し、データを追加・更新・削除する際に整合性を保てるようになります。
外部キーの仕組み
外部キーを設定すると、2つのテーブル間で、データの参照先と参照元で親子関係が成り立ちます。なお、参照先を親テーブル(マスターテーブル)、参照元を子テーブル(トランザクションテーブル)といいます。参照元(子テーブル/トランザクションテーブル)のカラムに外部キー制約を設定すると、参照先(親テーブル/マスターテーブル)の指定したカラムにある値しか指定できないよう制限されます。そのため、親テーブルに存在しない値を子テーブルのカラムに追加しようとしたり、子テーブルで登録のある値を親テーブルから削除しようとするとエラーになります。
たとえば、部署テーブルと従業員テーブルがある場合、従業員テーブルの部署欄には部署テーブルに登録されていない部署IDを登録できないというような感じです。後ほど詳しく紹介します。
外部キーの具体例
「子テーブルが親テーブルに存在しない値を持つことがないようにする」をわかりやすく具体例で説明します。
たとえば、下記のように「部署」テーブルと「従業員」テーブルがあるとします。
「従業員」テーブルの「部署ID」カラムに対し、「部署」テーブルの「ID」カラムを指定して外部キーを設定します。
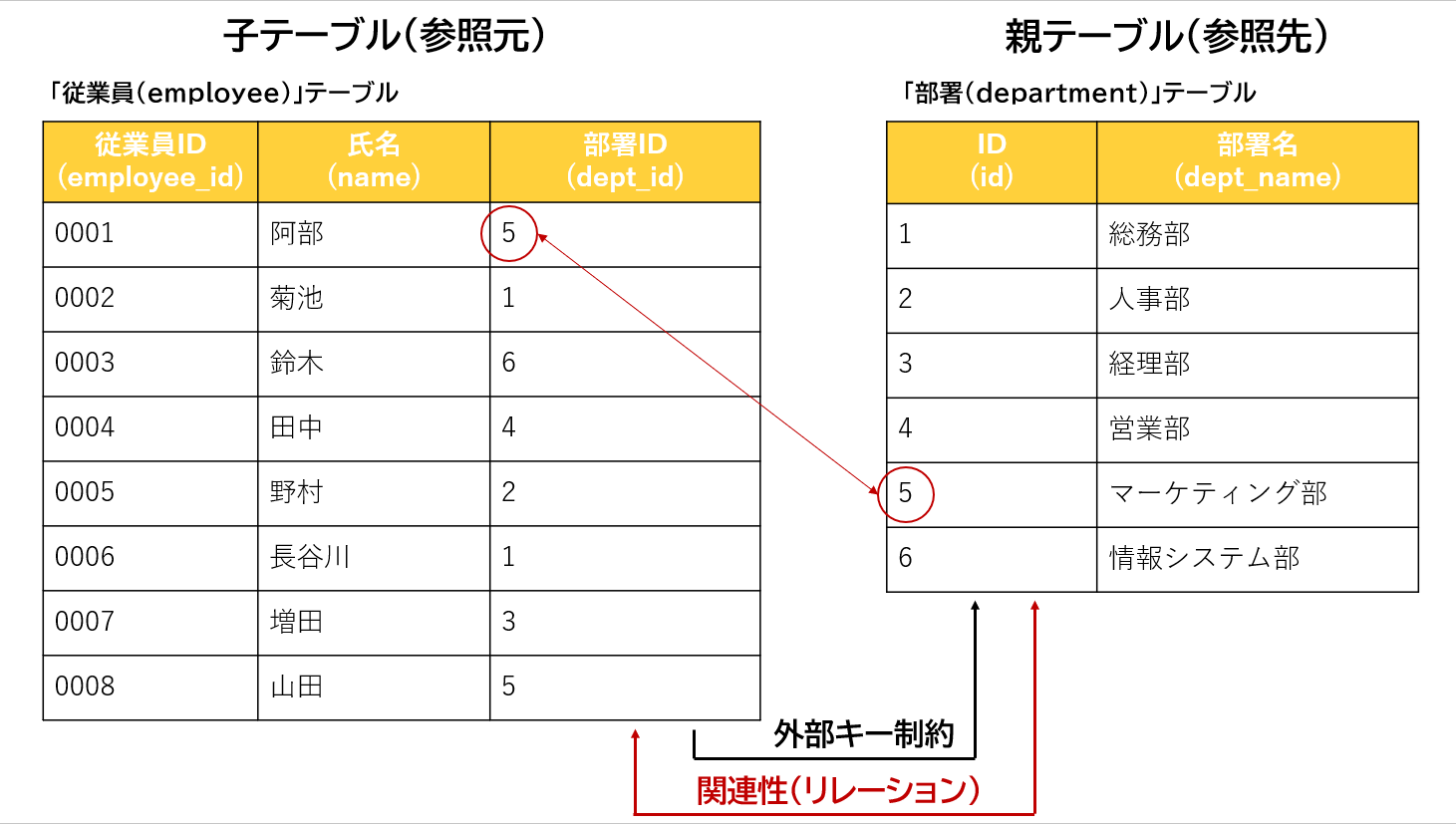
すると、「部署」テーブルに存在しない「部署ID」を「従業員」テーブルに登録できないようになり、この2つのカラムで整合性が保たれます。
つまり、「従業員」テーブルの「部署ID」カラムには、「部署」テーブルの「ID」カラムの「1~6」の値しか登録できないということですね!
外部キーと主キーの関係性
主キー(プライマリーキー)とは、レコードのうち、レコードを一意に識別する役割のあるカラムです。数値型のカラムを選ぶのが一般的ですが、文字列や日付などでも問題ありません。先ほどの「部署」テーブルでいうと「ID」カラム、「従業員」テーブルでいうと「従業員ID」カラムが主キーに適しています。同姓同名の社員や同じ部署の従業員がいても従業員IDで従業員を識別・管理できます。
そして、この主キーを参照するのが外部キーです。外部キーは、テーブル作成時に参照元の子テーブルにつけます。また、参照先(親テーブル)のカラムは、そのテーブルの主キーである必要があります。これは主キーが一意であり、かつNULL値(値が存在しない状態)ではいけないというルールがあるからです。参照先のカラムに重複したデータがあるとどのデータと結びつけるか識別できませんし、NULL値でも参照できません。
つまり、上記の場合は、「従業員」テーブルでは「従業員ID」カラムが主キー、「部署」テーブルでは「ID」カラムが主キー、そして、その「部署」テーブルでは「ID」カラムを参照する「従業員」テーブルの「部署」カラムが外部キーということになりますね!
外部キーの制約
外部キーを設定した場合、不整合を防ぐために下記の制約(参照整合性制約)が入ります。
1. 親テーブルに存在しない値を子テーブルに登録できない
2. 子テーブルに登録されている値を親テーブルから削除できない
この制約は参照元と参照先とで整合性が取れるよう、参照先に値が存在することを保証するものです。
それぞれ見ていきましょう。
サンプルテーブル
説明には次のサンプルテーブルを使用します。
「部署(department)」テーブル
| ID(id) | 部署名(dept_name) |
| 1 | 総務部 |
| 2 | 人事部 |
| 3 | 経理部 |
| 4 | 営業部 |
| 5 | マーケティング部 |
| 6 | 情報システム部 |
「従業員(employee)」テーブル
| 従業員ID(employee_id) | 氏名(name) | 部署ID(dept_id) |
| 0001 | 阿部 | 5 |
| 0002 | 菊池 | 1 |
| 0003 | 鈴木 | 6 |
| 0004 | 田中 | 4 |
| 0005 | 野村 | 2 |
| 0006 | 長谷川 | 1 |
| 0007 | 増田 | 3 |
| 0008 | 山田 | 5 |
この時、参照される側の「部署」テーブルが親、参照する側の「従業員」テーブルが子になります。たとえば、阿部さんの部署を知りたい場合、部署IDが「5」なので、「部署」テーブルの「ID」項目を参照すると「マーケティング部」であることが分かります。
親テーブルに存在しない値を子テーブルに登録できない
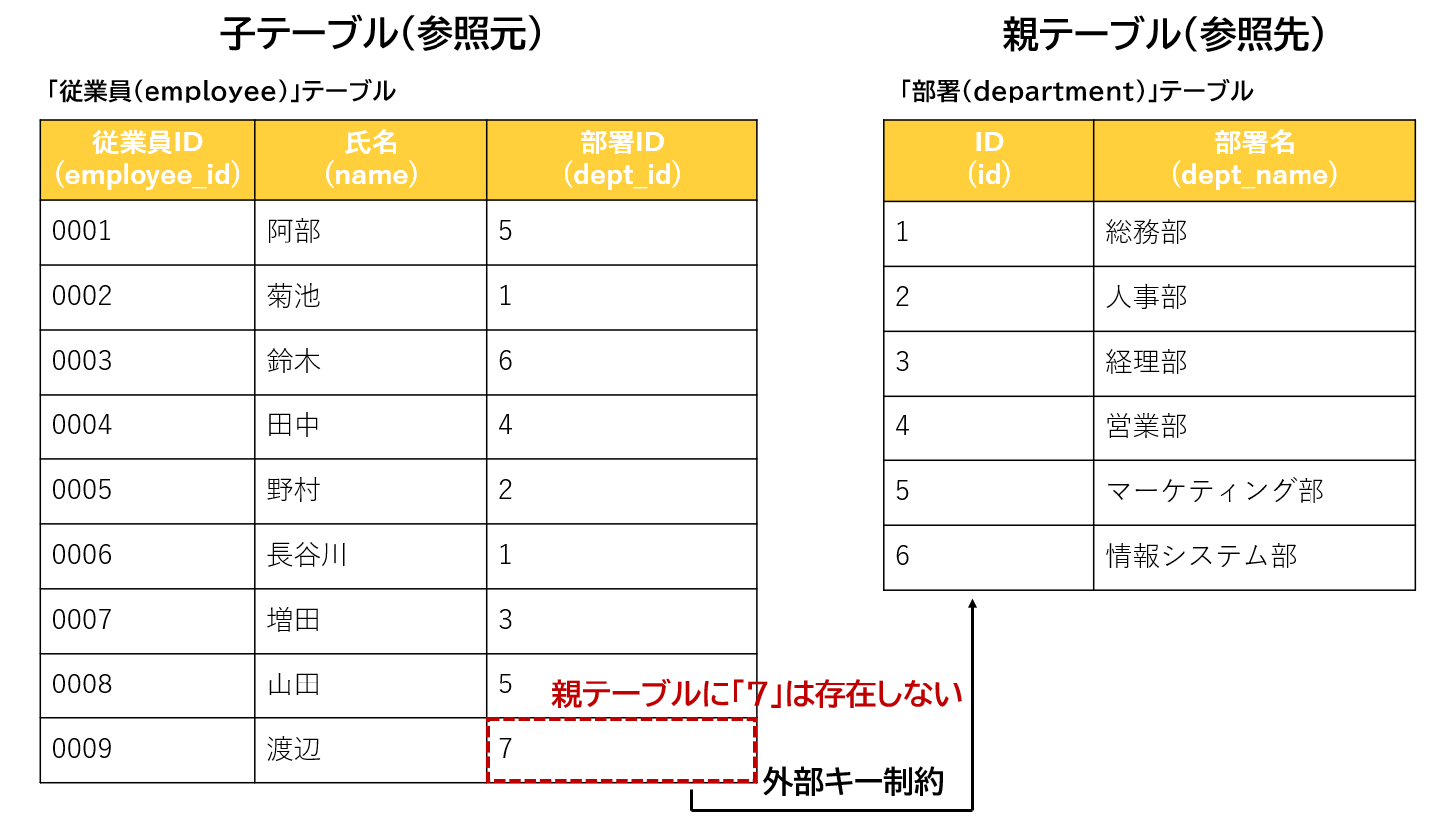
存在しない値を外部キーに設定できません。子テーブルに親テーブルに無いデータを追加すると、親子の整合性が崩れてしまいます。「部署」テーブルに下記のようなデータを登録するとします。
| 従業員ID(employee_id) | 氏名(name) | 部署ID(dept_id) |
| 0009 | 渡辺 | 7 |
【実行コード】
INSERT INTO employee VALUES(0009,'渡辺',7);しかし、親テーブルである「部署」テーブルには参照するデータがないので、「parent key not found」と記載されたエラーが出ます。
| ID(id) | 部署名(dept_name) |
| 1 | 総務部 |
| 2 | 人事部 |
| 3 | 経理部 |
| 4 | 営業部 |
| 5 | マーケティング部 |
| 6 | 情報システム部 |
| 7 | NULL |
【実行コード】
DELETE FROM department WHERE id=1;子テーブルに登録されている値を親テーブルから削除できない
子テーブルに外部キーとして登録されている値を親テーブルから削除・更新しようとすると「child record found」と記載されたエラーが出ます。
親テーブルからデータを削除するにはまず子テーブルの対象のデータを削除する必要があります。
外部キーの設定方法
コードを用いて実際にテーブルに外部キーを設定する方法を解説します。
外部キーは「テーブル作成時に設定する方法」と「既成テーブルに後から追加する方法」の2通りがあります。全項と同じサンプルテーブルを使用します。
テーブル作成時に設定する方法
新規テーブルの作成時に下記のクエリを追加することで、外部キーを設定できます。
FOREIGN KEY(参照元のカラム名) REFERENCES 参照先のテーブル名(参照先のカラム名));【使用イメージ1】
CREATE TABLE テーブル名(
カラム名 データ型 FOREIGN KEY,
カラム名 データ型,
カラム名 データ型,
……
);【使用イメージ2】
CREATE TABLE テーブル名(
カラム名 データ型 属性,
カラム名 データ型 属性,
カラム名 データ型 属性,
……
FOREIGN KEY(カラム名)
);外部キーを後から追加する方法
また、既存のテーブルに主キーを設定する場合は、「ALTER TABLE」文を使用します。
【使用イメージ】
ALTER TABLE テーブル名 ADD FOREIGN KEY (カラム名); テーブル作成
テーブル作成時に設定する方法を紹介します。
まず、データベース上に「従業員」テーブルと「部署」テーブルを作成します。
親テーブルの作成
【実行コード】
CREATE TABLE department(
id INTEGER NOT NULL PRIMARY KEY,
dept_name VARCHAR,
)
ENGINE=InnoDB DEFAULT CHARSET=utf8;親テーブルへのデータ追加
【実行コード】
INSERT INTO department VALUES('1','総務部');
INSERT INTO department VALUES('2','人事部');
INSERT INTO department VALUES('3','経理部');
INSERT INTO department VALUES('4','営業部');
INSERT INTO department VALUES('5','マーケティング部');
INSERT INTO department VALUES('6','情報システム部
');子テーブルの作成
【実行コード】
CREATE TABLE employee(
employee_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR,
dept_id INTEGER,
FOREIGN KEY(dept_id) REFERENCES department(id)
);
ENGINE=InnoDB DEFAULT CHARSET=utf8;子テーブルへのデータ追加
INSERT INTO employee VALUES('0001','阿部','5');
INSERT INTO employee VALUES('0002','菊池','1');
INSERT INTO employee VALUES('0003','鈴木','6');
INSERT INTO employee VALUES('0004','田中','4');
INSERT INTO employee VALUES('0001','野村','2');
INSERT INTO employee VALUES('0002','長谷川','1');
INSERT INTO employee VALUES('0003','増田','3');
INSERT INTO employee VALUES('0004','渡辺','5');以上で、「従業員」テーブルの「部署ID」カラムに外部キーを設定できました。
外部キーの整合性を確認する
ここからはコードを用いて実際に外部キーが整合性を保証しているか確認していきましょう。
親テーブルに存在しない値を子テーブルに登録できない
部署IDが「7」で従業員を登録してみます。下記のサンプルコードで確認できます。
【実行コード】
INSERT INTO employee VALUES('0009','渡辺','7');【実行結果】
ERROR……parent key not found……このように親テーブルに存在しない値を子テーブルに登録しようとするとエラーが出ます。なお、更新でも同様にエラーが起こります。
子テーブルに登録されている値を親テーブルから削除できない
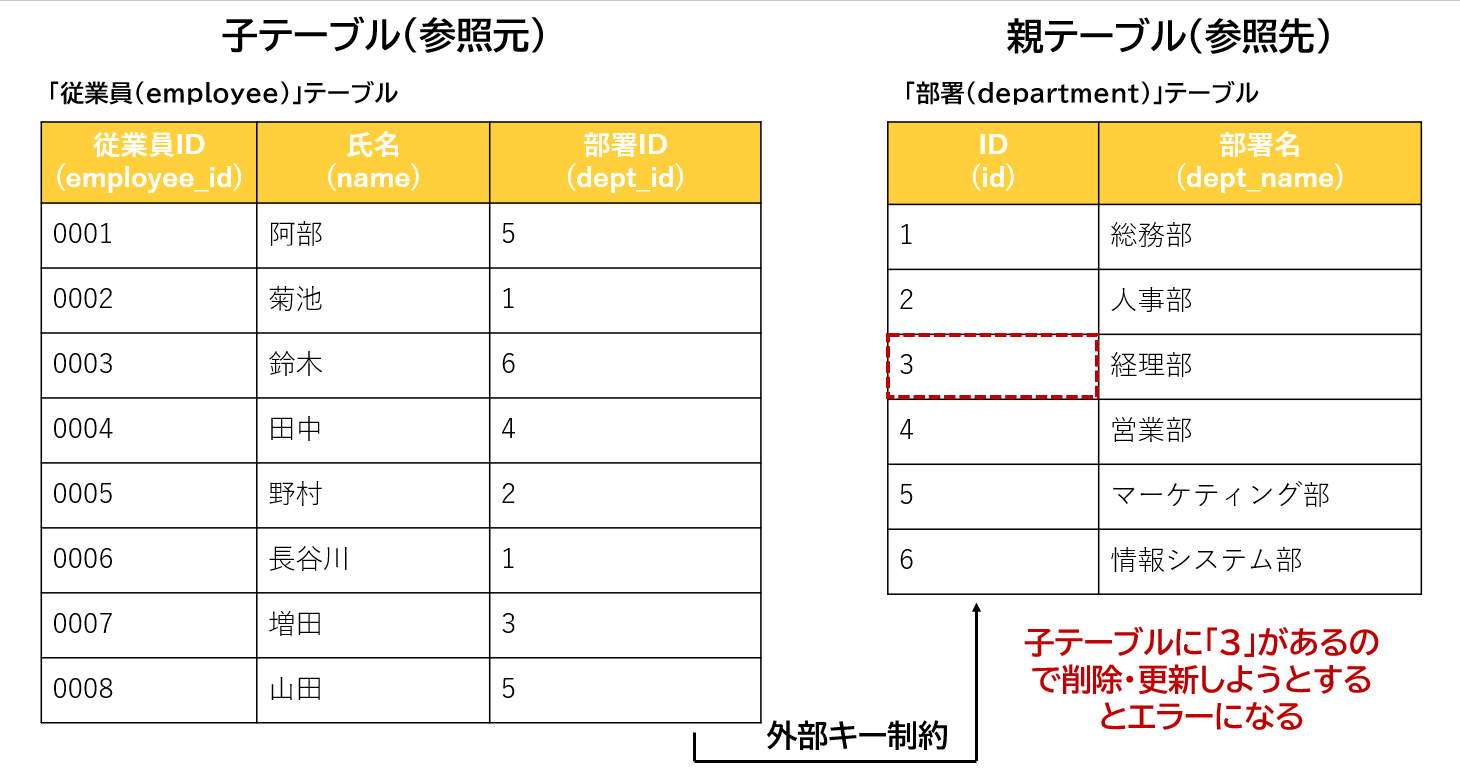
「部署」テーブルの「ID」カラムの「3」を削除してみます。
【実行コード】
DELETE FROM department WHERE id=3;【実行結果】
ERROR……child record found……外部キーを設定すると、参照先の親テーブルのデータに対しても、対象となる値が子テーブルで参照されている場合、削除・更新できない制約が設けられています。そのため親テーブルのデータを削除しようとするとエラーになって削除できません。
子テーブルに「3」があるので削除・更新しようとするとエラーになり削除できませんでした。削除する場合は、まず子テーブルのデータを削除する必要があります。
このように外部キーをつけることで親子間の整合性が保証されます。
親テーブルのデータを削除/変更する方法
データ削除:子テーブルのデータを削除>親テーブルのデータを削除
データ変更:親テーブルに変更対象のデータを追加>子テーブルのデータを変更>親テーブルのデータを削除
外部キーがついていても親テーブルのデータを削除・変更したいといったケースは出てきます。上記の手順を踏めば、データの整合性を保ちつつ親テーブルのデータを削除したり変更を加えたりできますが、手間がかかってしまいます。こういった場合、外部キーを設定する際に「ON UPDATE CASCADE」句や「ON DELETE CASCADE」句を付けることで親テーブルのデータ変更時と削除時に追随して、同じ値を持つ子テーブルのデータも自動的に変更/削除されます。
【実行イメージ】
……
FOREIGN KEY(参照元のカラム名) REFERENCES 参照先のテーブル名(参照先のカラム名)
ON UPDATE CASCADE ON DELETE CASCADE
);ここでも先述のサンプルテーブルを用います。
「部署(department)」テーブル
| ID(id) | 部署名(dept_name) |
| 1 | 総務部 |
| 2 | 人事部 |
| 3 | 経理部 |
| 4 | 営業部 |
| 5 | マーケティング部 |
| 6 | 情報システム部 |
「従業員(employee)」テーブル
| 従業員ID(employee_id) | 氏名(name) | 部署ID(dept_id) |
| 0001 | 阿部 | 5 |
| 0002 | 菊池 | 1 |
| 0003 | 鈴木 | 6 |
| 0004 | 田中 | 4 |
| 0005 | 野村 | 2 |
| 0006 | 長谷川 | 1 |
| 0007 | 増田 | 3 |
| 0008 | 山田 | 5 |
【実行コード】
CREATE TABLE employee(
employee_id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR,
dept_id INTEGER,
FOREIGN KEY(dept_id) REFERENCES department(id)
ON UPDATE CASCADE ON DELETE CASCADE
);
ENGINE=InnoDB DEFAULT CHARSET=utf8;「部署」テーブルの「経理部」を「3」から「7」に変更します。
UPDATE department SET id='3' WHERE id='7';すると、下記のように「従業員テーブル」の「部署ID」カラムが「3」から「7」に変更されているのがわかります。
| 従業員ID(employee_id) | 氏名(name) | 部署ID(dept_id) |
| 0001 | 阿部 | 5 |
| 0002 | 菊池 | 1 |
| 0003 | 鈴木 | 6 |
| 0004 | 田中 | 4 |
| 0005 | 野村 | 2 |
| 0006 | 長谷川 | 1 |
| 0007 | 増田 | 7 |
| 0008 | 山田 | 5 |
次に、先程変更した「部署」テーブルの「ID」カラム「7」のデータを削除します。
DELETE FROM department WHERE id='7';「ON DELETE CASCADE」が設定されているので、親テーブルで削除したデータと同じ値を持つ子テーブルのデータも削除されます。
子テーブルを確認すると下記のように「従業員テーブル」の「部署ID」カラムが「7」だった増田さんのデータが消えているのが確認できます。
| 従業員ID(employee_id) | 氏名(name) | 部署ID(dept_id) |
| 0001 | 阿部 | 5 |
| 0002 | 菊池 | 1 |
| 0003 | 鈴木 | 6 |
| 0004 | 田中 | 4 |
| 0005 | 野村 | 2 |
| 0007 | 増田 | 6 |
| 0008 | 山田 | 5 |
※コードにおける「Empty set」は検索結果が0件であることを示しています。
外部キー制約の種類
ON DELETE ~~ レコード削除時の振る舞い
ON UPDATE ~~ レコード更新時の振る舞い外部キー指定できる値は次のとおりです。どれを指定するかで参照先の削除や変更に対する振る舞いが変わり、変更を禁じたり変更を追随させたりできます。
RESTRICT
子テーブルで登録されている値を、親テーブルを削除または更新しようとするとエラーになります。指定を省略した場合、デフォルト値であるRESTRICTが設定されます。
NO ACTION
RISTRICT同様に親テーブルを削除または更新するとエラーになりますが、そのチェックはトランザクションの最後に行われます。
CASCADE
親テーブルを削除または更新すると子テーブル内の同じ値を持つカラムのデータに対しても削除または更新を行います。
SET NULL
親テーブルを削除または更新すると子テーブル内の同じ値を持つカラムのデータがNULLになります。
SET DEFAULT
現在これを指定するとテーブルの作成ができません。
外部キーを削除する方法
外部キーを削除するには、「ALTER TABLE テーブル名 DROP FOREIGN KEY 外部キーのID」で削除できます。外部キーのIDは、外部キーの設定時に自動で決まるので、名前を調べる必要があります。
「SHOW CREATE TABLE」文で確認しましょう。
【実行イメージ】
SHOW CREATE TABLE テーブル名;上記クエリで外部キーのIDを確認したら外部キーの削除を実行します。
【実行コード】
ALTER TABLE employee DROP FOREIGN KEY 外部キーのID;外部キーが削除できたことを確認できます。

外部キーの役割
データの整合性の保持
外部キーを設定することで、親テーブルにない値を子テーブルに登録できない制約がかかるので親子間のデータの整合性が保たれます。
データの特定
外部キーを設定することでデータの整合性が保たれるため、参照の追跡をすることでテーブル間で関連データを特定できます。外部キーを設定しなくてもテーブル間に関連性があればクエリで参照の追跡ができますが、外部キー制約が推奨されます。
外部キーを設定するメリット
- 親テーブルに存在しない値が外部キーに登録されることを防げる
- データの整合性を保てる
外部キーを設定する際の注意点
外部キーはデータの整合性を高められる一方で注意点もあります。
- 子テーブルのデータ追加・更新、親テーブルのデータ削除の度に整合性のチェックに時間がかかる
- データベースを跨ぐ制約はかけられない
このように、外部キーには注意点もあるので必要な場合に適宜設定するようにしましょう。
まとめ
外部キーを上手に活用することでテーブル間の整合性を保てるようになり、データの安全性や整合性を高められます。ただ、データの追加・更新・削除の際にかかる手間も増えるので目的によって適宜設定しましょう。
SQL関連記事
- RDBを操作するデータベース言語「SQL」とは?
- RDB以外のデータベース管理システム「NoSQL」とは?
- RDB管理システム「MySQL」とは?
- RDB管理システム「PostgreSQL」とは?
- RDB管理システム「SQL Server」とは?
- RDB管理システム「SQLite」とは?
- ブラウザ上でMySQLを管理できる「phpMyAdmin」とは?
- データを抽出する「SELECT」文
- データを追加する「INSERT」文
- データを削除する「DELETE」文
- データを更新する「UPDATE」文
- 抽出条件を指定する「WHERE」句
- 抽出条件を指定する「HAVING」句
- 複数の抽出条件をまとめる「IN」句
- 重複レコードを除外する「DISTINCT」
- 抽出範囲を指定する「BETWEEN」演算子
- 抽出条件を満たすレコードの存在の有無を調べる「EXISTS」句
- レコード件数を取得する集計関数「COUNT」関数
- レコードをグループ化する「GROUP BY」句
- 抽出結果を並び替える「ORDER BY」句
- テーブル間のデータを結合する「JOIN」句
- 内部結合「INNER JOIN」句
- 抽出結果を統合して表示する「UNION」句
- データの曖昧検索「LIKE」句
- 条件分岐処理「CASE」式
- 「NULL」の扱い方
SQLの勉強方法は?
書籍やインターネットで学習する方法があります。昨今では、YouTubeなどの動画サイトやエンジニアのコミュニティサイトなども充実していて多くの情報が手に入ります。
そして、より効率的に知識・スキルを習得するには、知識をつけながら実際に手を動かしてみるなど、インプットとアウトプットを繰り返していくことが重要です。特に独学の場合は、有識者に質問ができたりフィードバックをもらえるような環境があると、理解度が深まるでしょう。
ただ、SQLに限らず、ITスキルを身につける際、どうしても課題にぶつかってしまうことはありますよね。特に独学だと、わからない部分をプロに質問できる機会を確保しにくく、モチベーションが続きにくいという側面があります。独学でモチベーションを維持する自信がない人にはプログラミングスクールという手もあります。費用は掛かりますが、その分スキルを身につけやすいです。しっかりと知識・スキルを習得して実践に活かしたいという人はプログラミングスクールがおすすめです。
プログラミングスクールならテックマニアがおすすめ!

ITスキル需要の高まりとともにプログラミングスクールも増えました。しかし、どのスクールに通うべきか迷ってしまう人もいるでしょう。そんな方にはテックマニアをおすすめします!これまで多くのITエンジニアを育成・輩出してきたテックマニアでもプログラミングスクールを開講しています。
<テックマニアの特徴>
・たしかな育成実績と親身な教育 ~セカンドキャリアを全力支援~
・講師が現役エンジニア ~“本当”の開発ノウハウを直に学べる~
・専属講師が学習を徹底サポート ~「わからない」を徹底解決~
・実務ベースでスキルを習得 ~実践的な凝縮カリキュラム~
このような特徴を持つテックマニアはITエンジニアのスタートラインとして最適です。
話を聞きたい・詳しく知りたいという方はこちらからお気軽にお問い合わせください。
")




