
近年、ChatGPTをはじめとするクラウド型のAIサービスが広く使われるようになりました。
とても便利な一方で、入力した内容が外部のサーバーへ送信される仕組みのため、社内文書やソースコード、顧客情報といった機密性の高いデータを扱う場面では、セキュリティや接続環境が気になることもあるのではないでしょうか。
そこで注目されているのが「ローカルLLM」です。
ローカルLLMとは、自分のPCや社内サーバー上でAIを直接動かす仕組みのことで、入力したデータを外部に送らずに処理しやすい点が大きな特徴です。
文章生成や要約、コード生成といった作業を、ネット環境に依存せずに行いやすくなります。
ただし、ローカルLLMを快適に使うには、モデルの種類やPCのスペック、実行環境を自分で選ぶ必要があります。
「どのモデルを選べばいいのか」「どんなPCが必要なのか」と迷う方も多いはずです。
そこでこの記事では、ローカルLLMとは何かという基礎から、メリット・デメリットや活用シーン、おすすめのオープンソースモデルの比較、スペック選定の考え方、そしてOllamaを使った具体的な導入手順までを、初心者の方にも分かりやすく解説していきます。
ローカルLLMとは
ローカルLLMの仕組み
ローカルLLM(Large Language Model)とは、大規模言語モデルをクラウド上のサービスとして使うのではなく、自分のPCや社内サーバー上で直接動かす仕組みのことです。
データが外部のサーバーを経由しないため、入力した内容を外に送らずに処理できます。
ChatGPTのような一般的な生成AIサービスでは、入力した文章がインターネット経由で外部サーバーへ送られ、そのサーバー上で推論(テキストの生成や処理)が行われます。
一方、ローカルLLMでは、モデルを手元の端末や社内環境に置いて推論を行うため、外部サービスへのデータ送信を抑えやすい点が特徴です。
近年は、高性能なオープンソースモデルが広く公開され、個人向けのPCでも実用的に動かせるケースが増えてきました。
以前は数百GB規模のGPUメモリを要した大規模モデルも、量子化(モデルを軽量化する技術)の発展により、10〜20GB程度のVRAM(GPUに搭載されているメモリ)環境で動作する例が見られます。
なぜ今ローカルLLMが注目されているのか
ローカルLLMへの注目が急速に高まっている背景には、データの取り扱いへの懸念に加えて、もう一つ大きな理由があります。
それは、個人のPCでも扱えるオープンウェイトモデルが、急速に充実してきたことです。
Meta、Google、Alibaba、Mistral AIといった複数の企業が、性能の高いモデルを無償で公開する動きを続けており、2026年に入ってからもこの流れは加速しています。
たとえば、Googleが2026年4月に公開したGemma 4は、E2B・E4B・26B・31Bという幅広いサイズ展開があり、小さいものはノートPCやエッジ端末でも動かせるほど軽量です。Alibabaが手がけるQwen3.5は200以上の言語に対応した多言語モデルで、いずれもApache 2.0ライセンスのため商用利用もしやすくなっています。
こうした流れによって、ローカルLLMはひと握りの専門家だけが扱う技術ではなく、目的に応じて誰でも選べる身近な技術に変わりつつあります。
数年前まではローカルLLMを動かすには専門的な知識と高価なGPUが必須でしたが、モデルの軽量化技術(量子化)の進歩や、Ollamaのような扱いやすいツールの登場により、プログラミング初学者でも一般的なノートPCから試せるようになっています。
クラウド型LLMとの違い
ChatGPTのように、インターネット上のサーバーでAIを動かす形態を「クラウド型LLM」と呼びます。
ローカルLLMとクラウド型LLMには、主に処理する場所やデータの扱い、導入に必要な準備などに違いがあります。
大きな違いは「どこで処理を行うか」です。
クラウド型LLMは入力内容をインターネット経由で外部サーバーへ送って処理するのに対し、ローカルLLMは自分のPCや社内サーバーの中だけで処理が完結します。
この違いから、以下のような特徴の差が生まれます。
| 比較項目 | ローカルLLM | クラウド型LLM |
|---|---|---|
| 処理する場所 | 自分のPCや社内サーバー上 | 提供元の外部サーバー上 |
| データの扱い | 外部への送信を抑えやすい | 入力内容を外部サーバーへ送信 |
| 導入のしやすさ | 環境構築やモデル選定が必要 | 登録すればすぐに使い始めやすい |
| コスト | 機器の準備や電力・管理の手間がかかる | 利用量に応じた料金が発生しやすい |
| 性能 | PCスペックやモデルサイズに左右される | 高性能なモデルを利用しやすい |
| 向いている用途 | 機密データの処理やオフライン利用 | 手軽さや高い精度を求める作業 |
クラウド型AIは手軽に使い始めやすい一方で、ローカルLLMはデータを手元の環境で扱いやすい点が強みです。
そのため、用途や扱うデータの種類に応じて使い分けることが重要です。
ローカルLLMのメリット
ここでは、ローカルLLMならではのメリットを4つ紹介します。
【データを外に出さない安心感】
ローカルLLMの最大の魅力は、入力した内容を外部のサーバーに送らずに処理できることです。
開発中のソースコードや、顧客情報を含むデータなど、外に出したくない情報を扱う場合でも、安心して試しやすくなります。
ただし、端末の管理やアクセス制御が甘ければ別の経路で情報が漏れる可能性はあるため、「送らないから絶対安全」というわけではない点は覚えておきましょう。
【通信環境に左右されない速さ】
処理がすべて手元のPCで完結するため、通信環境の影響を受けにくいのも特徴です。
ネットワーク経由の待ち時間が発生しないため、応答も比較的速く、回線が不安定な場所や
オフライン環境でも文章生成やコード作成といった作業を進められます。
【API利用料がかからない】
ChatGPTのようなクラウド型サービスは、使えば使うほど利用料がかさむ従量課金制が
一般的です。
その点、ローカルLLMは一度環境を整えてしまえば、その後は使用回数を気にせず何度でも無料で使い続けられます。
【自由にカスタマイズできる】
オープンウェイトモデルであれば、モデルのライセンス条件を確認した上で、自分の用途に
合わせてモデルの振る舞いを調整する「ファインチューニング」や、特定の役割を持たせた
オリジナルモデルの作成も可能です。
学習や個人開発の一環として、AIの仕組みそのものに触れられる点も、ローカルLLMならではの楽しさと言えます。
ローカルLLMのデメリット・注意点
ここでは、ローカルLLMを使う上で知っておきたいデメリット・注意点を3つ紹介します。
【モデルによって性能に差がある】
ひとくちにローカルLLMといっても、日本語の自然さ、長文への対応力、コーディング精度はモデルによって大きく異なります。
たとえば同じ数十億パラメータ規模のモデルでも、対応言語数や処理できる文章の長さはさまざまです。
「試したら思ったより使えなかった」という場合、モデル自体が用途に合っていない可能性もあるため、複数のモデルを比較しながら選ぶことをおすすめします。
【相応のPCスペックが必要になる】
モデルのサイズによっては、高性能なGPUや大容量のメモリが求められます。
パラメータ数が大きいモデルほど、必要なメモリの目安も大きくなるため、今使っているPCでは動作しない、または動いても実用に耐える速度が出ないケースも珍しくありません。
【自分でメンテナンスする必要がある】
クラウド型サービスのように自動でアップデートされる仕組みがないため、新しいバージョンのモデルへの入れ替えや、動作しなくなった際の対応は、基本的に自分で行う必要があります。
継続して使い続けるには、メンテナンスの手間が多少かかることは理解しておきましょう。
ローカルLLMの活用事例
実際にどのような場面でローカルLLMが活用されているのか、具体的な事例を紹介します。
個人開発・学習での活用シーン
【コーディングの学習・補助】
自分のPC内でコードの生成やレビュー、デバッグの相談を完結させたい場合に活用できます。
学習中の未完成なコードや、個人開発中のアプリのソースコードをAIに読み込ませる際も、外部にデータを送らずに質問できるため、安心して試行錯誤を重ねられます。
エラーメッセージをそのまま貼り付けて原因を尋ねる、といった使い方も手軽に試せます。
【手元の文書・メモの検索】
検索拡張生成(RAG)という仕組みを使うと、自分の技術メモや学習用ドキュメントをAIに読み込ませて、必要な情報だけを引き出せるようになります。
従来は手作業でファイルを探していた情報も、AIに聞くだけで数秒で見つけられるようになり、自分だけのナレッジベースとして活用できます。
【オフライン環境での学習・作業】
インターネット接続がない環境でも、文章生成や要約、コードの作成といった作業を進められます。
移動中の新幹線内や、通信環境が不安定な場所、あるいは通信量を気にしたくない環境でも、学習や開発の手を止めずに済む点は大きな利点です。
【学習用チャットボットの作成】
Modelfileなどの仕組みを使って、特定の役割を持たせたオリジナルのチャットボットを
作ることもできます。
たとえば「プログラミング用語だけをやさしく解説してくれる講師役」のようなキャラクターを設定し、自分専用の学習パートナーとして育てていくことも可能です。
【個人開発中のアプリへの組み込み】
OllamaのAPIを経由して、自作のWebアプリやツールにAI機能を組み込むこともできます。
チャット機能を持つ個人開発アプリや、入力内容を要約するミニツールなど、AIを使った
アプリ開発の練習環境として、コストをかけずに試作を重ねられます。
業界別の活用シーン
個人利用だけでなく、実際の企業でもローカルLLMの導入が進んでいます。
エンジニアを目指す方にとって、将来携わる可能性のある現場をイメージする参考として紹介します。
【医療業界】
電子カルテシステムと連携させ、患者データを外部に出さずに、画像診断の補助や診療記録からの情報抽出などに役立てる取り組みが進んでいます。
【製造業】
工場の生産ライン上で、通信環境に依存せずリアルタイムに動作するAIとして、品質検査や異常検知に活用されるケースがあります。
【金融業界】
顧客の取引データや投資情報といった機密性の高い情報を、外部に送信せず社内だけで分析する用途に利用されています。
【法務・法律関連】
過去の契約書や判例のデータベースを社内環境で管理し、類似案件の検索や文書作成を効率化する取り組みが行われています。
ローカルLLMのおすすめオープンソースモデルと2026年の主要トレンド
先ほど確認したVRAM容量・動かせるモデルサイズをもとに、実際にどのモデルを選べばよいか見ていきましょう。
用途やパラメータ数に応じた最適なモデルの棲み分け
LLM選定では「パラメータ数」が重要な指標になります。
パラメータ数とは、機械学習モデルが学習によって調整する変数 (パラメータ) の多さを表す数値のことを言います。
パラメータ数が多いほどにモデルは複雑になり、より高度な表現や幅広い知識に対応することができます。
一般的な目安は以下の通りです。
【3B〜8Bクラス】
| シリーズ | モデル名 | Ollamaでの取得コマンド |
|---|---|---|
| Qwen | Qwen3.5 4B | ollama pull qwen3.5:4b |
| Gemma | Gemma 4 E4B | ollama pull gemma4:e4b |
| Phi | Phi-4 Mini | ollama pull phi4-mini |
| DeepSeek | DeepSeek-R1 8B(蒸留版) | ollama pull deepseek-r1:8b |
用途:
・チャット
・要約
・軽いコーディング
・モバイル環境
例:
・Phi-4 Mini
・Qwen3.5 4B
・Gemma 4 E4B
少ないメモリで動作するため、ノートPCでも扱いやすいサイズとなっています。
【14B〜32Bクラス】
| シリーズ | モデル名 | Ollamaでの取得コマンド |
|---|---|---|
| Qwen | Qwen3-Coder 30B(コーディング特化・MoE) | ollama pull qwen3-coder:30b |
| DeepSeek | DeepSeek-R1 32B(蒸留版) | ollama pull deepseek-r1:32b |
| Mistral | Devstral Small 24B(エージェント型開発向け) | ollama pull devstral:24b |
用途
・本格的な開発支援
・ドキュメント生成
・RAG構築
・エージェント運用
例:
・Qwen3.5 27B
・DeepSeek系中型モデル
・Mistral Small
現在のローカルLLMにおける最も人気のゾーンです。
24GB前後のVRAM環境で高い性能を得られます。
【70B以上】
| シリーズ | モデル名 | Ollamaでの取得コマンド |
|---|---|---|
| Llama | Llama 3.3 70B | ollama pull llama3.3:70b |
| DeepSeek | DeepSeek-R1 70B(蒸留版) | ollama pull deepseek-r1:70b |
| Qwen | Qwen2.5 72B | ollama pull qwen2.5:72b |
用途
・研究開発
・高精度推論
・大規模エージェント
例:
・Llama 70B系
・Qwen 72B系
高品質ですが、複数GPUや大容量VRAMが必要になります。
2026年のトレンドとしては、「巨大モデルを無理に動かす」よりも「20B~30B級の高性能モデルを量子化して快適に使う」方向へ移行しています。
日本語性能とコーディング能力で選ぶ主要OSSモデルの特徴
2026年7月9日現在における、ローカルLLMの主流は以下のモデル群です。
中国Alibabaが開発するオープンソースモデルです。
近年のローカルLLM界隈では最も評価が高いモデルの一つであり、日本語性能・多言語性能・コーディング能力のバランスに優れています。
Qwen3系はApache 2.0ライセンスを採用しており、商用利用しやすい点も特徴です。
特にQwen3-Coderはプログラミング用途で高く評価されており、コード生成やリファクタリング、エージェント型開発との相性が良好とされています。
例:
・Qwen3.5
・Qwen3 Coder / Qwen3 Coder Next
Metaが開発する代表的なオープンモデルです。
研究コミュニティやツール群との互換性が高く、多くの派生モデルが存在します。
特にLlama 3系以降は汎用性能が向上し、文章生成からコーディングまで幅広く対応可能です。
例:
・Llama 4 Scout
推論能力や数学性能に強みを持つモデル群です。
特にDeepSeek-R1系の蒸留モデルは、比較的小さなサイズでも高い推論性能を発揮することで注目されています。
複雑な問題解決や論理的思考を必要とする用途で人気があります。
例:
・DeepSeek-R1
・DeepSeek-V4
フランスのMistral AIが開発するモデルです。
比較的小型ながら高い性能を持ち、推論速度も優秀です。
リソースが限られた環境で快適に動作するため、個人利用者からの支持も高くなっています。
例:
・Mistral Large 3
・Mistral Small 4
Googleが公開する軽量モデルです。
比較的少ないメモリで動作しながら高い品質を維持しており、小規模環境向けの有力候補となっています。
例:
・Gemma 4
ローカルLLMのスペック選定基準とハードウェアインフラの要件
モデルの実行速度を左右するVRAM容量と量子化の仕組み
ローカルLLMを使用する上では、VRAM容量が特に重要となります。
例えば32Bモデルを実行する場合、通常精度では数十GB以上のVRAMを必要とするためです。
そこで、VRAMの消費量を削減するために利用されるのが、「量子化(Quantization)」と呼ばれる技術です。
量子化とは、パラメータのデータサイズを圧縮して軽量化する技術のことを言います。
同じモデルでも、量子化形式によってサイズがどれだけ変わるのか、実際の数値で見てみましょう。
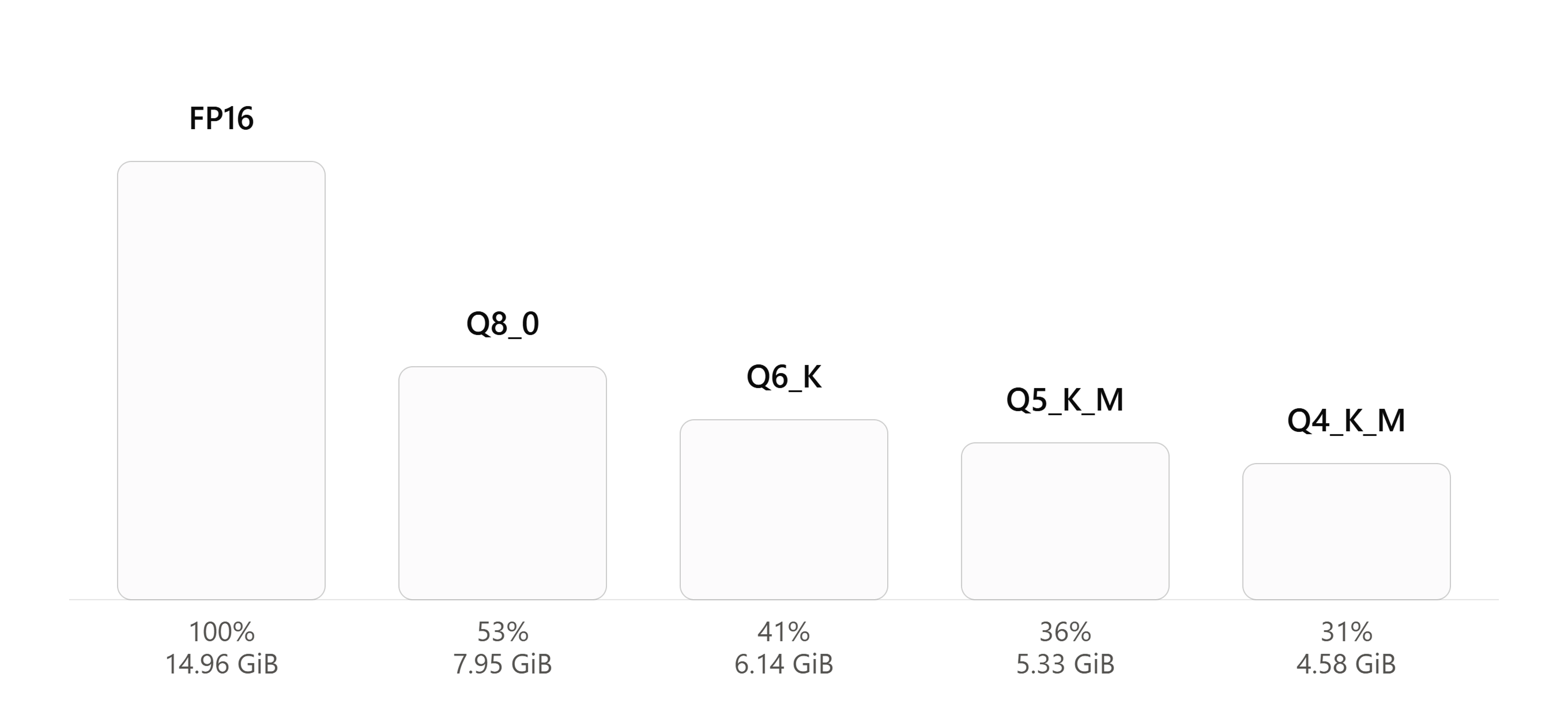
7Bモデルの実測値(llama.cpp公式README記載のベンチマークに基づく参考値)。
モデルやパラメータ数によってサイズは変動します。
代表的な形式には以下があります。
- FP16
- Q8
- Q6
- Q5
- Q4
FP16は16bit、Q8は8bitで表現するといったように、数字が小さいほどメモリ消費は減少します。
ただし量子化率を高めすぎると、
- 推論品質低下
- 日本語性能低下
- コーディング精度低下
などの問題が発生するため、どの程度まで軽量化を行うかは動作環境や使用目的を考慮した上で決める必要があります。
(個人仕様の場合は、Q4軽量化でもほとんど問題なく動作します)
実用上では、以下の量子化方法がよく使用されています。
- Q4_K_M:省メモリ重視
- Q5_K_M:品質と速度のバランス
- Q6_K:品質重視
VRAM容量別・動かせるモデルサイズの目安
ここまでのVRAMと量子化の関係を踏まえて、実際に「自分のPCでは何Bクラスのモデルまで動かせるのか」を早見表にまとめました。
ご自身のPCのVRAM容量と照らし合わせながら確認してみてください。
| VRAM容量 | 動かせる目安 | 主な用途 | 想定される環境 |
|---|---|---|---|
| 8GB前後 | 3B〜8Bクラス (Q4量子化) |
チャット、簡単な要約、 軽いコーディング補助 |
内蔵GPUのノートPC、 エントリー向けGPU |
| 12〜16GB | 7B〜14Bクラス (Q4〜Q5) |
本格的なコーディング支援、 文章生成 |
RTX 4060 Ti 16GB等 |
| 24GB前後 | 14B〜32Bクラス (Q4〜Q6) |
RAG構築、 エージェント運用 |
RTX 4090 24GB等 |
| 48GB以上/ ユニファイド メモリ96GB〜 |
70B級 | 研究開発、 高精度推論 |
複数GPU構成、 Mac Studio等 |
あくまで目安のため、同じVRAM容量でもモデルや量子化形式によって余裕度は変わります。
表より少し余裕を持ったクラスを選ぶと、動作が安定しやすくなります。
ご自身のPCのVRAM容量は、WindowsならタスクマネージャーのGPU画面、MacならAppleメニューの「このMacについて」から確認できます。
Windowsでの確認方法はこちらのタスクマネージャー「パフォーマンス」タブの見方の解説記事(参考情報)を併せてご覧ください。
Macをお使いの方は、Apple公式サポート「Macのシステム情報を取得する」のページで、メモリ容量の確認手順が案内されています。
NVIDIA製GPUとApple Siliconユニファイドメモリのコストパフォーマンス比較
ローカルLLMを本格的に動かす場合、現在のハードウェア選択は主に NVIDIAと Apple Siliconの二択となります。
大まかな違いは以下の通りです。
【NVIDIA】
現在もローカルLLMの主流となっているハードウェアです。
CUDAによる最適化が進んでおり、多くの推論ソフトウェアがNVIDIAを前提に設計されています。
| GPU | VRAM | 実勢価格帯(税込・目安) | 向いているモデルサイズ |
|---|---|---|---|
| RTX 4060 Ti 16GB | 16GB | 約9.5万円〜 | 7B〜14Bクラス |
| RTX 4070 Ti Super | 16GB | 約9万円〜(中古中心・新品はほぼ流通終了) | 7B〜14Bクラス |
| RTX 4090 | 24GB | 約40万円前後(中古中心・新品は流通終了) | 14B〜32Bクラス |
| RTX 5090 | 32GB | 約58万円〜70万円 | 32B以上 |
例:
・RTX 4060 Ti 16GB
・RTX 4070 Ti Super 16GB
・RTX 4090 24GB
・RTX 5090 32GB
メリット:
・推論速度が速い
・対応ソフトが豊富
・最新技術への対応が早い
デメリット:
・VRAM単価が高い
・消費電力が大きい
高い処理速度を誇る反面、VRAMの容量の問題により、巨大なモデルを動かそうとすると単価が高くついてしまいます。
処理性能を第一に考える場合は、NVIDIAの方が使用に適しています。
【Apple Silicon】
MシリーズMacでは、CPU・GPU・メモリが統合されたユニファイドメモリを利用しています。
96GBや128GBのメモリを搭載したものであれば、大型モデルをそのまま載せることも可能です。
メリット:
・静音性が高い
・省電力
・大容量メモリを共有可能
デメリット:
・GPU性能はNVIDIAに劣る
・一部ツールの最適化が不足
Apple Siliconは電力消費が少なく静音性も高いため、AI推論を利用する頻度が高いユーザーにおすすめのハードウェアです。
本格的な学習が必要なく、チャットUIなどで日常的に使用する場合は、 Apple Siliconの方がコストを低く抑えられます。
| モデル | メモリ構成 | 価格(目安) | 向いているモデルサイズ |
|---|---|---|---|
| Mac Studio (M4 Max) |
36GB〜128GB | 328,800円〜 | 7B〜14Bクラス (36GB構成の場合) |
| Mac Studio (M3 Ultra) |
96GB〜512GB | 668,800円〜 (最大構成は2,263,800円) |
32B〜70B級 (96GB以上の構成の場合) |
上記の点から、一般的には、
- 速度重視 → NVIDIA
- 静音性と省電力重視 → Apple Silicon
という選び方がされています。
Ollamaを用いたローカルLLMの具体的な導入手順と基本コマンド
環境構築からモデルのダウンロードまでの実践ステップ
ローカルLLM初心者に最も人気のある実行環境がOllamaです。
Ollamaは複雑な推論環境を簡単に構築できるツールであり、Windows・macOS・Linuxに対応しています。
インストールは、公式サイトに記載されている各コマンドを実行するか、インストーラーをダウンロードして実行します。
インストールが完了したら、以下のコマンドを実行して正常にインストールできたかを確認しておきましょう。
ollama --version% ollama --version
ollama version is 0.31.1動作に問題がなければ、モデルのダウンロードに移行可能です。
ダウンロード方法は、以下のように 「ollama pull」 コマンドで導入したいモデルを指定します。
ollama pull qwen3.5:4bモデルのダウンロードが開始されます。完了まで数分かかる場合があります。

モデルのダウンロードが完了すると、「success」と表示されます。

ダウンロード完了後は、「ollama run」 コマンドでモデルを使用できます。
ollama run qwen3.5:4bollama runコマンドを実行すると、ダウンロードしたモデルが起動します。
>>> Send a messageと表示されたら、プロンプトを入力して利用を開始できます。
ollama run qwen3.5:4b
>>> Send a message (/? for help)実務で今すぐ使える実行・操作の基本コマンド集
実際の業務でも使用可能なコマンドをいくつか紹介します。
【インストール済みモデルの一覧表示】
ollama listローカルに保存されているモデルを一覧で確認できます。
【モデルの実行】
ollama run qwen3.5:4b実行すると、チャットモードで起動されます。
【モデルの削除】
ollama rm qwen3.5:4b不要になったモデルは、このコマンドで削除できます。
【モデルの情報表示】
ollama show qwen3.5:4bモデルのサイズや設定内容などを確認することができます。
【サーバーモードを起動】
ollama serveREST APIとして利用できる状態になります。
【API経由で実行】
curl http://localhost:11434/api/generate \
-d '{
"model":"qwen3",
"prompt":"Pythonのfor文を説明してください"
}'これにより、自作アプリやWebシステムと連携できます。
【カスタムモデルの作成】
FROM qwen3.5:4b
SYSTEM あなたはプログラミング講師です例えば上記内容をModelfileとして保存し、以下のコマンドを実行すると独自モデルを作成できます。
ollama create mymodel -f Modelfile最後に
ローカルLLMは現在、生成AIを自分のPCやサーバー上で実行する技術として急速に普及しています。
高性能オープンソースモデルの登場や量子化技術の進歩により、一般向けGPUやApple Silicon環境でも十分な性能を得られるようになり、導入のハードルは大幅に下がりました。
「ひとまずお試しで使ってみたい」 という初心者の方でも、小型モデルであれば既存環境に導入できる可能性は十分にあるので、この機会にぜひ利用してみてはいかがでしょうか?




