
皆さんは、Webスクレイピングというものをご存知でしょうか?
Webスクレイピングとは、Webサイトにある膨大なデータの中から、必要な情報のみを抽出して取得することを言います。
Pythonには、Webスクレイピングに特化した「Beautiful Soup」 というライブラリが存在します。
今回の記事では、Beautiful Soupのインストール方法や使い方について解説をしていきたいと思います!
Beautiful Soupとは?
Beautiful Soup は、HTML や XML ファイルから必要なデータを抽出するための Python ライブラリです。
Beautiful Soup を使用することで、Webサイトから取得したいデータだけを簡単に抽出することができます。
Webサイトから必要な情報を取得をするまでの手順は、大きく分けて以下の3つに分けられます。
- データの取得
- データの解析
- データの保存
Webサイトから取得したデータには、文章だけでなくサイトを構成するタグなど数多くの情報が含まれているため、手動で必要な情報だけを抜き出すのは困難です。
そこで、データの内容を解析して欲しい情報だけを抽出してくれるのが、Beautiful Soupの主な機能となっています。
Beautiful SoupでWebスクレイピング
Beautiful Soupの主な機能について紹介したところで、続けてインストール方法と簡単な使用方法についても解説していきたいと思います。
Beautiful Soupをインストールする
まずは、Beautiful Soupを端末にインストールしましょう。
(※Pythonのインストールがまだの場合は、事前に済ませておく必要があります)
Beautiful Soupは、以下の pipコマンドでインストールすることが出来ます。
pip install beautifulsoup4Beautiful Soupはあくまでデータ解析用のライブラリとなっているため、解析元となるデータを取得することはできません。
そのため、実際に Beautiful Soupを使用する際は、別途ライブラリを用意するなどしてデータを取得する必要があります。
今回の記事では、「Requests」というライブラリを使用してデータを取得します。
こちらも pipコマンドでインストールが可能です。
pip install requestsスクレイピング対象のページにアクセスする
ライブラリのインストールが完了したら、まずは Requestsを使って情報を取得したい Webサイトにアクセスしましょう。
Requestsを使用するには、初めにライブラリをインポートする必要があります。
以下のようにコードを記述して、Requestsをインポートしましょう。
【サンプルコード】
import requestsインポートが完了したら、 「requests.get()」 で取得したいサイトのURLを指定します。
指定に問題がなければ、これだけでデータを簡単に取得することができます。
今回は例として、Wikipediaのメインページにアクセスしてみます。
【サンプルコード】
import requests
url = 'https://ja.wikipedia.org/wiki/メインページ'
#データの取得
response = requests.get(url)
#エンコーディング
response.encoding = response.apparent_encoding
print(response.text)上記のコードを実行すると、以下のように取得したデータ内容がコンソールに表示されます。
【実行結果】
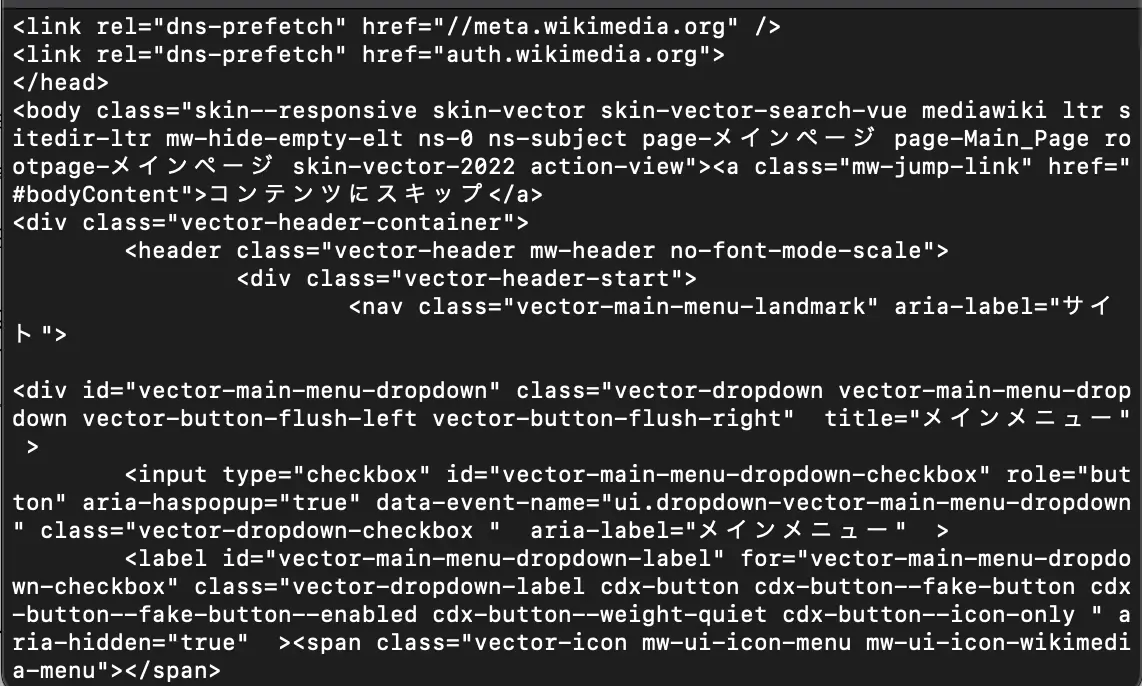
画像に写っているのはごく一部のデータのみですが、これだけでも大量の情報があることが見て取れますね。
このデータを元に、Beautiful Soupを使って必要な情報の抽出を行います。
なお、サイトに何度もアクセスするとサーバーに大きな負荷がかかってしまうため、一定時間ごとのアクセス回数には注意が必要です。
ページをスクレイピングする
データの取得が無事に完了したら、そのデータを元に Beautiful Soupでスクレイピングします。
Beautiful Soupを使用する際は、先ほどと同様にライブラリをインポートする必要があります。
以下のように記述して、Beautiful Soupをインポートしましょう。
【サンプルコード】
from bs4 import BeautifulSoupインポートが完了したら、まずは取得したデータの解析 (パース) を行います。
パースをする際の基本構文は、以下のように記述します。
【基本構文】
BeautifulSoup(解析対象のデータ, 使用するパーサー)1つ目の引数には、解析対象となるデータを指定します。2つ目の引数には、解析時に使用するパーサーを指定します。
Beautiful Soupで指定できるパーサーには、いくつかの種類があります。
| パーサー名 | モジュール名 | 特徴 |
|---|---|---|
| Python’s html.parser | html.parser | 標準ライブラリのため追加インストール不要 |
| lxml’s HTML parser | lxml | C言語バインディングによる高速処理が可能 |
| lxml’s XML parser | xml | XML構文のパースにも対応 |
| html5lib | html5lib | HTML5仕様に準拠した正しい処理が可能 |
lxmlなどの外部ライブラリを使用する場合は、そちらも合わせて事前にインストールしておきましょう。
【インストール用コマンド】
pip install lxmlパースが完了することで、HTMLタグや CSSセレクタなどを基準に、取得したい内容を抽出できるようになります。
取得したデータ全体を確認したい場合は、以下のコードでインデントすると内容が見やすくなります。
【サンプルコード】
soup.prettify()【実行結果】
以下は、h2タグ内のテキストを全て抽出する場合のサンプルコードです。
【サンプルコード】
import requests
from bs4 import BeautifulSoup
url = 'https://ja.wikipedia.org/wiki/メインページ'
response = requests.get(url)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.content, 'html.parser')
for h2 in soup.find_all("h2"):
print(h2.get_text())【実行結果】
選り抜き記事
新しい記事
新しい画像
強化記事
今日の一枚
今日は何の日 6月19日
風物詩
ポータル
インフォメーション
ウィキメディアプロジェクトfind_all() は、引数に指定したタグと一致するデータを全て取得することができるメソッドです。
取得した内容の中にはタグも含まれているため、get_text()でタグ内のテキスト部分のみを抜き出しています。
今回の記事では簡単な内容のみを紹介しましたが、この他にも様々な方法で抽出したい内容を指定することができます。
スクレイピング結果が文字化けする場合はどうする?
基本的には上記の方法でスクレイピングすることができますが、ケースによっては内容が文字化けしてしまう場合があります。
その際は、以下のように記述して対応しましょう。
【サンプルコード】
soup = BeautifulSoup(response.content.decode(文字コード, "ignore"), "html.parser")BeautifulSoupの使用時に文字化けが起きてしまう原因は、元データ側で使用されている文字コードと、BeautifulSoup側でのパース処理時に使用される文字コードが異なる場合があるからです。
上記のコードは、使用する文字コードを任意のものに指定するコードになります。
文字コードのみの指定ではエラーが発生してしまうため、「”ignore”」 でエラーを無視するよう指定しています。
文字コードの部分には、元データ側で使用している文字コードを記述します。
例えば、使用している文字コードが utf-8 の場合は、以下のようなコードになります。
【サンプルコード】
soup = BeautifulSoup(response.content.decode("utf-8", "ignore"), "html.parser")なお、元データ側の文字コードは 「response.encoding」 で確認することができます。
まとめ
いかがでしたか?
今回は、Beautiful Soupのインストール方法や使い方について解説しました。
トレンド把握や競合分析、或いはマーケットリサーチなど、必要な情報をサイトから収集したい場合に Webスクレイピングは必須の技術となります。
Beautiful Soupは応用できる幅が広いため、使いこなせるようになるまでは少々難しさを感じてしまうかもしれませんが、非常に便利な機能の一つです。
ぜひ今回を機に、詳しい使い方を覚えて活用してみてくださいね!
Pythonの勉強方法は?
書籍やインターネットで学習する方法があります。昨今では、YouTubeなどの動画サイトやエンジニアのコミュニティサイトなども充実していて多くの情報が手に入ります。
そして、より効率的に知識・スキルを習得するには、知識をつけながら実際に手を動かしてみるなど、インプットとアウトプットを繰り返していくことが重要です。特に独学の場合は、有識者に質問ができたりフィードバックをもらえるような環境があると、理解度が深まるでしょう。
ただ、Pythonに限らず、ITスキルを身につける際、どうしても課題にぶつかってしまうことはありますよね。特に独学だと、わからない部分をプロに質問できる機会を確保しにくく、モチベーションが続きにくいという側面があります。独学でモチベーションを維持する自信がない人にはプログラミングスクールという手もあります。費用は掛かりますが、その分スキルを身につけやすいです。しっかりと知識・スキルを習得して実践に活かしたいという人はプログラミングスクールがおすすめです。
プログラミングスクールならテックマニアがおすすめ!

ITスキル需要の高まりとともにプログラミングスクールも増えました。しかし、どのスクールに通うべきか迷ってしまう人もいるでしょう。そんな方にはテックマニアをおすすめします!これまで多くのITエンジニアを育成・輩出してきたテックマニアでもプログラミングスクールを開講しています。
<テックマニアの特徴>
・たしかな育成実績と親身な教育 ~セカンドキャリアを全力支援~
・講師が現役エンジニア ~“本当”の開発ノウハウを直に学べる~
・専属講師が学習を徹底サポート ~「わからない」を徹底解決~
・実務ベースでスキルを習得 ~実践的な凝縮カリキュラム~
このような特徴を持つテックマニアはITエンジニアのスタートラインとして最適です。
話を聞きたい・詳しく知りたいという方はこちらからお気軽にお問い合わせください。



で任意の要素を取得・操作する")
の使い方")
